
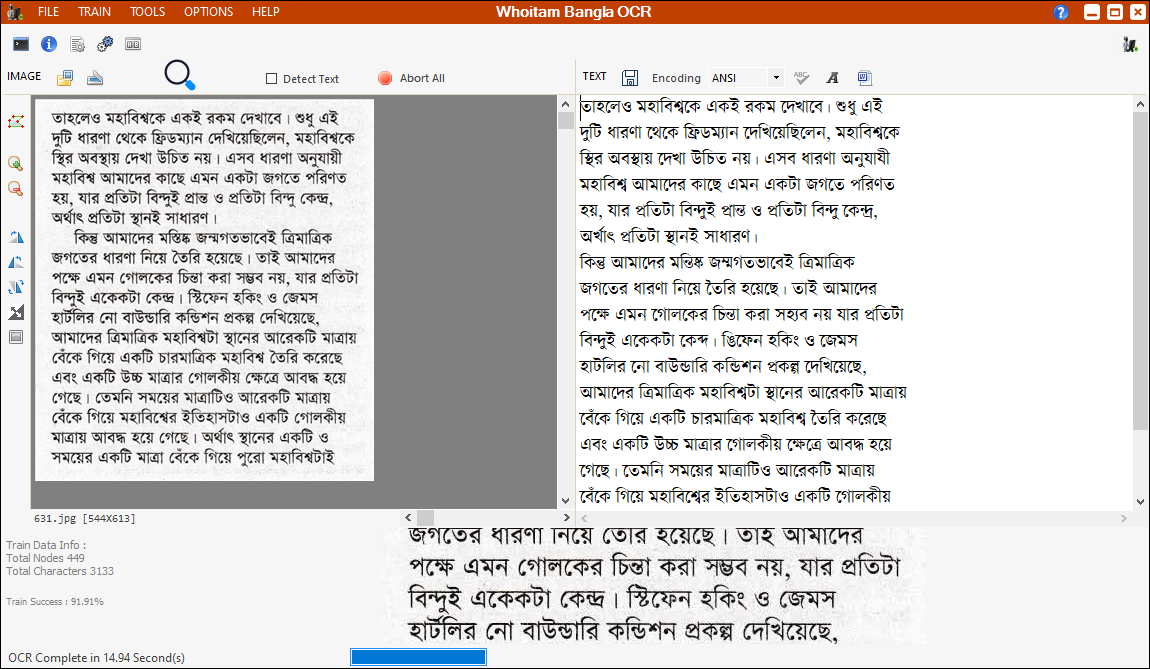
It is a Bangla OCR. It recognizes only Bangla characters from image and makes editable text in ANSI or Unicode output. Here train data’s are provided only standard from of characters and distorted, small characters are not provided as train data. So, it works good with 300 dpi (Scanner Setting) scanned image. Some new technologies are used in here. It is accurate near 95% in word level. It is written in pure Microsoft DOT NET C# 2012 and without any external dependencies. First select a text area as a polygon by “New Selection” button and clicking on image. Then click “Start OCR”. If you select output in Unicode, then you can perform spell check. Our words collection for spell check is small. So, spell check can’t perform good.
It requires Microsoft DOT NET Framework 4.5 or higher. Please install it from Microsoft installer. The download link is http://go.microsoft.com/fwlink/p/?LinkID=225702
*Note 1: Some antivirus can detect it as a virus. But it is not a virus. False positive detection occurs because, we have provided a protection cover to protect this from decompiling, crackers and this protection cover some real virus uses too. So, some antivirus detects it as a virus for only this protection cover. We have not supplied this software sample to the antivirus companies to avoid this false positive detection. Because, we always update and improve Whoitam Bangla OCR.
*Note 2: After installed start it by “Run as administrator”.
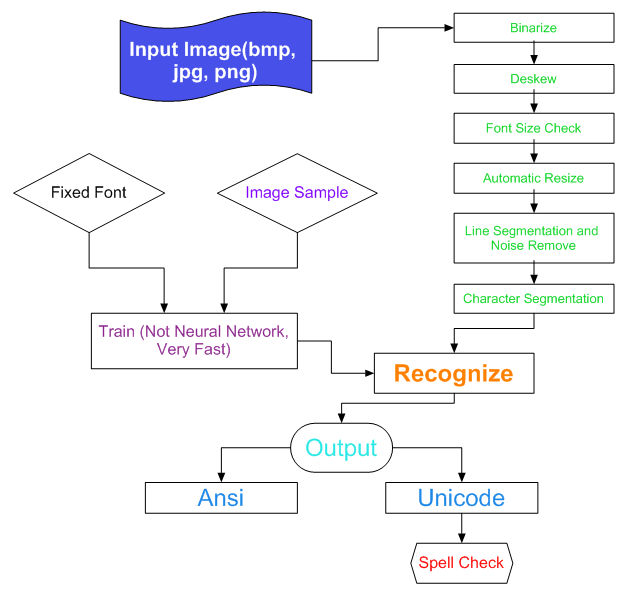
The Workflow of Whoitam Bangla OCR:
System Requirement:
- Operating System: Minimum Windows 7 or higher (32 Bit or 64 Bit)
- Processor: Dual Core or higher
- RAM: 2 GB or more
- Disk Space: 500 MB or more
- Microsoft .Net Framework 4.5 or higher installed from Microsoft website or Microsoft installer